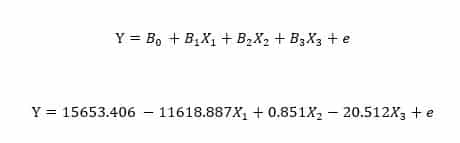Multiple Regression SPSS GSSS Dataset Project – Multiple regression is a statistical analysis technique used to examine the relationship between a dependent variable (the outcome or response variable) and two or more independent variables (predictors or explanatory variables). In other words, it allows you to predict the value of the dependent variable based on the values of the independent variables.
SPSS (Statistical Package for the Social Sciences) is a widely used software for statistical analysis in various fields, including social sciences, business, and other research domains. It provides tools to perform a wide range of statistical analyses, including multiple regression.
The GSS (General Social Survey) dataset is a well-known dataset in the social sciences, particularly in sociology. The GSS is a survey conducted in the United States that collects data on a wide range of topics, such as demographics, attitudes, and behaviors. Researchers use the GSS dataset to analyze trends and relationships in society.
Multiple Regression Background
A “Multiple Regression SPSS GSSS Dataset” refers to the application of multiple regression analysis using the GSS dataset within the SPSS software. This could involve analyzing the relationship between one or more dependent variables (e.g., income, happiness, political affiliation) and several independent variables (e.g., age, education, gender) using the GSS dataset and the statistical capabilities of SPSS.
Research question:
The effect of age, number of children, respondent’s income and weekly working hours on the overall family income.
Research hypothesis:
H0: age, number of children, respondent’s income and weekly working hours has no effect on the family’s income.
H1: age, number of children, respondent’s income and weekly working hours has an effect on the family’s income.
Research design:
The research design adopted in this study is referred to as causal relationship approach with the aim of analyzing the effect of age, number of children, respondent’s income and weekly working hours on the overall family income. According to (Cooper & Schindler, 2014), the main concern in causal relationship approach is with how one variable(s) affects or is responsible for changes in another variable(s).
Dependent variable:
The dependent variable(Y) used was the family income. The income was measured in constant dollars showing how much income the whole family generates.
Independent variables:
(X1) the first independent variable is the number of children in each family
(X2) respondent’s income measured in constant dollars is the second variable
(X3) weekly working hours is the last independent variable which is measured by the number of hours the respondent works in a week.
Control variables:
Control variables are the held constant in order to assess the relationship between other variables (Allison, P. D., 1990). This research has included two control variable which are the sex of the respondents and their ages. These variables are added because in a typical society the sex affects the income of the worker and the higher the age the greater the experience hence increased income. By setting the two variable as control we excluded their effect on the model.
Descriptive Statistics
Mean
Std. Deviation
N
FAMILY INCOME IN CONSTANT DOLLARS
56199.86
48030.037
32
NUMBER OF HOURS USUALLY WORK A WEEK
39.69
12.880
32
NUMBER OF CHILDREN
2.59
1.720
32
RESPONDENT INCOME IN CONSTANT DOLLARS
31446.56
30660.828
32
AGE OF RESPONDENT
47.88
12.289
32
RESPONDENTS SEX
1.69
.471
32
Model Summary
Model
R
R Square
Adjusted R Square
Std. Error of the Estimate
Change Statistics
R Square Change
F Change
df1
df2
Sig. F Change
1
.744a
.554
.468
35040.004
.554
6.449
5
26
.001
a. Predictors: (Constant), RESPONDENTS SEX, AGE OF RESPONDENT, NUMBER OF HOURS USUALLY WORK A WEEK, NUMBER OF CHILDREN, RESPONDENT INCOME IN CONSTANT DOLLARS
Coefficients
Model
Unstandardized Coefficients
Standardized Coefficients
T
Sig.
B
Std. Error
Beta
1
(Constant)
15653.406
51982.735
.301
.766
AGE OF RESPONDENT
1684.865
667.954
.431
2.522
.018
NUMBER OF CHILDREN
-11618.887
4835.608
-.416
-2.403
.024
RESPONDENT INCOME IN CONSTANT DOLLARS
.851
.330
.543
2.579
.016
NUMBER OF HOURS USUALLY WORK A WEEK
-20.512
767.766
-.006
-.027
.979
RESPONDENTS SEX
-21296.312
16254.030
-.209
-1.310
.202
a. Dependent Variable: FAMILY INCOME IN CONSTANT DOLLARS
Results:
A multiple regression test was carried out to test if number of children in a family, respondent’s income and number of hours worked weekly affect the overall family income. From the SPSS output the independent variable affect the dependent variable. The model summary table show that r=0.74, r2=0.554 thus, there is a positive correlation between the predictor and the response variables.
Additionally, 55.4% of the variation in the family income (M= 56199.86, SD= 48030.037, N= 32) is explained by variations in the dependent variables. From the f value F= 6.449, p=0.001, the f change tests for overall significance of the independent variable in the model and p value< 0.05 we therefore reject the null hypothesis (Anderson et al., 2000) and conclude that the independent variable are statistically significance hence they affect the family income.
The coefficient tables gives rise to the models regression equation:
Where:
Y= family income in constant dollars
X1= number of children in the family
X2= respondent’s income in constant dollars
X3= number of hours worked weekly.
e= noise
X1 (M=2.59,SD=1.720,N=32) is statistically significant at t=-2.403,p=0.024 because the p value is less than 0.05, the effect size is at -11618.887 such that an increase in children number in the family ceteris paribus leads to a decrease in family income by 11618.887dollars.
X2(M=31446.56, SD=30660.828, N=32) is also statistically significant at t=2.579, p= 0.016 being less than 0.05 we reject the null hypothesis and conclude that the respondent’s income affects the family income. The effect size is such that an increase in the respondent’s income by one dollar ceteris paribus leads to an increase in the family income by 0.851.
X3(M=39.69, SD=12.880,N=32) is not statistically significant, t=-0.027, p=0.979,the p-value being greater than 0.05 we accept the null hypothesis that respondent’s number of weekly working hours does not affect the family’s income.
In conclusion we establish from the statistics that, other than sex and age of the respondent the family’s income is affected by the number of children in the family and the respondent’s income holding other factors constant.
References
Allison, P. D. (1990). Change Scores as Dependent Variables in Regression Analysis. Sociological Methodology, 20, 93.
Cadotte, M. W., & Davies, T. J. (2018). Randomizations, Null Distributions, and Hypothesis Testing. Princeton University Press.
Cooper, D. R., & Schindler, P. S. (2014). Business Research Methods. New York, NY: McGraw Hill Education.
David, Anderson R., Burnham, K. P., & Thompson, W. L. (2000). Null hypothesis testing: Problems, prevalence, and an alternative. Journal of Wildlife Management, 64(4), 912-923
Did you find any useful knowledge relating to multiple regression SPSS GSSS datasets in this post? What are the key facts that grabbed your attention? Let us know in the comments. Thank you.
Marketing in a Digital World: A Case Study of Harrods Digital Marketing
Digital Marketing at Harrods – The advancement in technology has ushered a new era of e-commerce. The internet has pushed the traditional marketing strategy into the back burners as business organizations struggle to keep up with increasing levels of competition due to globalization.
Business organizations have to keep up with the dynamic needs of the modern day customer who is well informed and has access to a variety of choices at the touch of his fingers. The proliferation of smart phones has further delocalized the internet and the customer is constantly bombarded by marketing gimmicks and adverts the moment he/she goes online.
The internet has further introduced new methods of serving the customer off site thus nullifying the need of the customer presenting himself/herself physically on site. Various business organizations have embraced the challenge proffered by the digital world. Manufacturers, wholesalers and retailers have all adopted electronic marketing in order to maintain their presence in the market.
This paper will investigate a retail organization, Harrods, located in the United Kingdom and appraise the role of marketing management in light of the challenges posed by the digital age.
Brief History of Harrods
Harrods is a retail organization located in London, United Kingdom. It belongs to the category of department stores among the various types of retail organization. Its beginnings can be traced to 1849 when one Henry Charles Harrod set up a grocery store at Brompton Road, south of Hyde Park in the Kensington Borough.
Harrods began the enterprise in single room with two assistants and an assistant in his employ. The grocery store soon expanded into medicines, perfumes, stationery, fruits and vegetables and the retailer soon acquired the adjoining buildings in order to cater for the business expansion. By 1881, Harrods had a total of one hundred people in its employ (Callery, 1991).
In December, 1883, the retailer would experience bad fortune when a fire razed it to the ground. However, the owner the organization made a quick turn around and rebuilt on the same location. Charles Harrod went on to sell his stock via stock market floatation to Edgar Cohen for a total of £120,000 in 1889. The new store became known as Harrod’s Stores Limited.
Harrods was the first retailer in England to put an escalator into their store. Harrods then underwent exchange of ownership two times. The House of Fraser acquired in 1959 before selling it off to the Fayed brothers in 1985. The Fayed brothers would eventually sell off the retailer to Qatar Holdings in May 2010.
Qatar Holdings is the sovereign wealth fund of Qatar. Harrods is currently Europe’s largest department stores and it occupies a five acres in term so land and as of 2013, it had 12, 000 employees working in its 330 departments. In 2017, its revenues were £2 billion and had a net income of £233.2 million. Harrods store is spread over seven floors and remarkable food halls. Harrods is listed on the London Stock Exchange (Callery, 1991).
The Retail Business Environment in the United Kingdom
Harrods departmental store is located in the United Kingdom, particularly in London where retail business is an important aspect of the London business environment. Retail organizations serve to link producers and consumers, serves as a source of employment and contributing to the overall economy of London.
Despite the rise of Ecommerce which has made it possible for producers to engage directly with end users, retail organizations still continue to play an essential role as go-betweens for consumers and manufacturers. This is because retailers have a unique array of skills and talents specific to their role of an intermediary.
The average household in the United Kingdom spends about £160 on purchasing retail products every week which amounts to almost to a quarter of the mean average spending (Barrett, 2015). This is a significant amount of money spent at retail outlets and is a source of employment for 0.4 million residents of London.
A larger proportion of these individuals work in the sales and customer care departments (Barrett, 2015). In addition, the retail sector is a source of part time jobs for young people. 21% of employees in the retail sector are aged 24 years and below in comparison to 9% in other sectors of the economy. The retail sector further serves to employ a significant number of women as 54% of personnel in the retail sector are women in comparison to 44% in other sectors (Barrett, 2015).
As of 2014, there were approximately 43,000 retail firms in the City of London (Barrett, 2015). These retail shops are distributed all over the City although there is a high density of retail firms in central London. The retail sector occupies approximately 17.0 million square metres of floorspace in the London.
The three boroughs of Westminster, Croydon and Kensington have the largest areas of retail floor space. These boroughs have at least fifty retail outlets for every square kilometer. The highest numbers of customers in these retail shops are local residents although a number of tourists frequent them.
In addition to the above economic impacts of retail stores, retail firms stimulate significant amounts of personal and goods transportation as well as creating a demand for the other segments of the economy which includes construction, logistics and warehousing.
The retail sector in London is growing and retail firms will continue to have more consumers than in the past. The population of London experienced a growth of 1.0 million between 2003 and 2013 having risen from 8.4 million during that time to 9.4 million. The UK government estimates that the London population will further grow by 1.7 million to 10.1 million by 2036.
This would translate to an additional 0.9 million households as new markets for the retail sector. The surrounding regions of London will also experience population growth from with the South and East of London expected to increase by 1.5 million and 1.0 million respectively by 2036. The number of tourists is expected to continue rising especially with the ease of restrictions on issuance of visas to Chinese tourists.
These figures indicate that the retail sector will continue to grow. The retail sector will have more and more older customers. For instance, the number of customers over the age of 90 was 0.6% in 2013 but this number will rise to 1.3% by 2036 (PWC, 2013).
Finally, the household income of London residents will rise faster than the growth rate thus implying that the consumers will be richer and thus will have increased spending power which would be a boon for retailers. Other demographic changes that will have a significant effect on the retail industry include the fact the average Londoner will have a higher literacy level ,will experience better health and that the population of Londoners will become more diversified.
Advances in information technology have changed the behaviour of the average London consumer as he is far more likely to segment his shopping procedure. Unlike in the past where a customer would discover a product in the retail shop, conduct research on the product at the shop by asking attendants questions and then pay for the good at the till, the increased literacy levels and access to the internet would trigger the consumer to do each of the activities at different places.
The customer might discover the product on Facebook while at work, conduct research on Google about the product while in bus and purchase the good online while at home.
Electronic and mobile-commerce are two new frontiers which consumers attach importance to when carrying out their shopping. E-commerce is steadily rising and online purchases in 2014 accounted for 11% of all sales values in London. E-commerce also encourages frugality as the customer can conduct online research for the best deals thus saving himself some amount of money.
E-commerce further encourages use of online discount retailers and consumers will tend to avoid high end retail department stores. Industry experts have also highlighted the development of a new trend whereby shoppers buy their groceries more often. This implies that consumers have intensified their frugality by buying less goods but more often in order to cut on wastage and possibly have access to fresh groceries. All of which are key to a successful digital marketing strategy.
The increased participation of London residents in the sharing economy has also reduced the amount of goods purchased by consumers. An example of sharing economy is Airbnb. In this setup, people rent out their unused assets to others.
As a result, there is reduced buying as more and more people rent out already purchased goods. Finally, the average London consumer places more value on enjoying the shopping experience rather than just having to successfully purchasing the good.
The average consumer gains more pleasure from browsing good online at the comfort of his home rather than physically examining goods which is much more expensive in terms of transport and time. Consumers are less likely to visit a retail store if the store does not provide an enjoyable experience (UKCES, 2014).
Challenges Faced by Harrods
Harrods is located in the centre of London in the Kensington Borough. In light of these, Harrods faces tough competition from 43,000 retail firms located in London. Its Kensington location makes it vulnerable to competition that numbers to 50 retail outlets per square kilometre.
Despite the fact that the population shall increase as well as the spending power, the reality is the number of retail industries will continue to increase thus further reducing the number of customers available for grabs (Wolny, 2014).
The changing characteristics of the average customer poses a threat to the number of customers that Harrods has can capture. The rise in E-commerce implies that many clients would prefer not to travel physically to the big stores as they could easily browse and research online for good.
Customers can get access to a variety of products offered by different competitors and thus discern for themselves where to get the best deals. Harrods is a premier store and this means that the prices of its goods are on the higher side. However, the pricing has not been an issue as clients have been coming to the store and accessing quality products hence they have had no complaints with the price.
With the rise of online shops and digital marketing, clients will choose cheaper goods from discount stores and will not be interested in quality. This will result in a significant loss of customers for the establishment.
Furthermore, Harrods has been a tourist attraction location for quite long, but the advent of online shops will offer tourists with alternate places to visit thus skipping the Harrods store or spending less time at the store. Harrods also shall face challenges as the age group of consumers becomes considerably older.
Older customers will not have the energy nor the time to walk around the 5-acre department store. Older customers would prefer to look up goods over the internet and have them delivered to their homes (Shin-Young, 2018). The fact that the London community has picked on the sharing economy culture implies that Harrods will have fewer customers venturing into the establishment over time. Harrods was facing a challenge to provide a new podium that could counter to market dynamics and changes in client behavior.
Digital-Marketing-Dissertation-Topics
Transformation to Counter Changes to Digital Marketing
Harrods has instituted various changes in order to adapt its operations to technological changes. The store instituted new brand strategy, marketing, communications, visual merchandising, CRM, customer service, digital, personal shopping and media campaigns and operations.
Harrods further employed new members of staff in the upper echelons of management to spear head change that is affecting business operations. Harrods has went the way of providing product information more on online forums through text and images. It has set up a website where consumers can look at the catalogue of its goods, check the prices, the specifications and make online purchases as well as have the goods delivered to their doorsteps.
The online interface allows its consumers to give their opinions, suggestions, reviews and create their personalised shopping and wish lists. Harrods has also set up an online rewards scheme, flash sales and discounted goods in order to stimulate purchase of goods (Hart, Doherty and Ellis‐Chadwick, 2000). The Harrods website makes use of cookies to study their consumer behaviour and thus detect patterns
Consequently, the website will direct the consumer to their favourite sections of its online catalogue as well as making suggestions through use of artificial intelligence (Sunny and Anael, 2016). By allowing customers to make personal reviews about products that they have purchased, Harrods has managed to make use of consumers to conduct online promotion for products by Harrods.
In order to ensure that the customers do not post negative reviews, Harrods have invested in skilled employees, excellent information technology infrastructure, secure online financial transactions, fast transportation and courier services, a 24 hour online presence of customer service staff and an effective response team to cater for customer queries and complaints(Dennis, Joško Brakus and Alamanos, 2013).
In light of the stiff competition at home, Harrods website is accessible to international consumers who can place orders and have their products delivered regardless of their geographical location in the world. Harrods is no longer limited by its physical stores but has ventured into online sale of goods across international borders.
The premium store has also adopted the use of digital signage. This sort of signage entails screens in public spaces displaying video. Content may comprise advertisements, community information, entertainment and news. Digital signage aims to communicate with shoppers, hold them captive while they are in the mood to shop.
The retailer has invested in digital signage advertisements that are highly charged with factual information and thus arouse an intellectual experience. Category and brand decisions are made 40% of the time while the client is in the store. Digital signage works by inducing sensory and effective experiences and provoking approach behavior towards the products on advertisement with the end result being that the consumer becomes loyal to the store.
Digital signage serves to create an impression within the consumer that he is modern as the ambience increases his self-esteem and he becomes proud to be associated with the store due to it being fashionable and trendy (Dennis, Joško Brakus and Alamanos, 2013).
The next frontier to digital signage that Harrods invested in is interactivity, as well as using cameras to determine and identify gender and age of the consumer. These will empower Harrods to comprehend and customize its content to clients more effectively, while brands will have justification of their advertising investments. The store also wants to install several large, high-impact video walls which would facilitate the interaction of the consumer with a mobile device, to interact with content from mobile to screen and vice versa (Kent et al, 2018).
Digital Marketing at Harrods
Harrods invested £200m in the redevelopment of its store in order to cater for the new needs of its transformed customer. The changes in its store included the setting up of the men’s super-brands floor, a new look toy department and the conclusion of its fine watches and jewelry division. The store also set up a women’s shoe store that it labeled shoe haven Shoe haven comprises reserved premium shopping suites for clients.
To capture women age 20 to 40, it set up a Candy Crush-style game christened Stiletto Wars where the top scorer earned a gift card to expend on shoes. To access the game, consumers had to download Harrods’ magazine app. Since 2010, the retailer has put out more than 35 magazines in print, digital and app formats from reaching 300,000 plus subscribers. This was a chief part of Harrods’ marketing stratagem to attract consumers.
More than 13,000 consumers downloaded the app to play in the game, and they each spend an average of 19 minutes playing (Wagner, Schramm-Klein and Steinmann, 2018). The Stiletto Wars game has been a success as over two hundred media shops wrote articles about the game and tied it to the opening of the Shoe Haven. The stories went viral on social media and eighty million consumers read the stories on social media. Harrods set up an E-commerce department to produce innovative ideas for the store to remain competitive in the digital market.
Harrods has also capitalized on social media communication in order to communicate the store’s brand values i.e., British, Luxury, Innovation, Sensation and Service. The store provides its customers with free access to 4G internet while shopping at the premises which serves to enhance the customer experience.
References List
Dennis, C., Joško Brakus, J. and Alamanos, E. (2013). The wallpaper matters: Digital signage as customer-experience provider at the Harrods (London, UK) department store. Journal of Marketing Management, 29(3-4), pp.338-355.
Callery, S., 1991. Harrods, Knightsbridge: The Story of Society’s Favourite Store. Random House (UK).
Kent, A., Dennis, C., Cano, M. B., Helberger, E., & Brakus, J. (2018). Branding, marketing, and design: Experiential in-store digital environments. In Fashion and Textiles: Breakthroughs in Research and Practice (pp. 275-298). IGI Global.
Hart, C., Doherty, N. and Ellis‐Chadwick, F. (2000). Retailer adoption of the Internet – Implications for retail marketing. European Journal of Marketing, 34(8), pp.954-974.
Wagner, G., Schramm-Klein, H. and Steinmann, S. (2013). Effects of cross-channel synergies and complementarity in a multichannel e-commerce system – an investigation of the interrelation of e-commerce, m-commerce and IETV-commerce. The International Review of Retail, Distribution and Consumer Research, 23(5), pp.571-581.
Wagner, G., Schramm-Klein, H. and Steinmann, S. (2018). Online retailing across e-channels and e-channel touchpoints: Empirical studies of consumer behavior in the multichannel e-commerce environment. Journal of Business Research.
Wolny, J. (2014). Marketing transformations: Re-thinking marketing, digital first. Journal of Direct, Data and Digital Marketing Practice, 16(2), pp.150-151.
Talikoti, S. (2019). Digital Marketing: The Vital Vitamin for The Future Marketing. SSRN Electronic Journal.
Sunny, E. and Anael, O. (2016). Mobile Marketing in a Digital Age: Application, Challenges & Opportunities. British Journal of Economics, Management & Trade, 11(1), pp.1-13.
Barrett, A. (2015). Retail in London: Looking Forward.
Ellis-Chadwick, F. (2013). History of online retail.
Hart, C., & Laing, A. (2014). The consumer journey through the high street in the digital era. Southampton: University of Southampton.
PWC. (2013). Demystifying the Online Shopper: 10 Myths of Multichannel Retailing. New York: PWC.
UKCES. (2014). Understanding Skills and Performance Challenges in the Wholesale and Retail Sector. London: UKCES.
Did you find any useful knowledge relating to digital marketing at Harrods in this post? What are the key facts that grabbed your attention? Let us know in the comments. Thank you.
Supply Chain Resiliency and Its Impact on Organizational Performance
Introduction
Impact Of Supply Chain Resilience On Organisational Performance – Supply chain resiliency is a critical aspect of organizational performance, as disruptions in the supply chain can have a significant impact on a company’s ability to deliver products and services to its customers. In this blog post, we will explore the concept of supply chain resiliency and its impact on organizational performance, and discuss strategies that companies can use to enhance their resiliency.
What is Supply Chain Resiliency?
Supply chain resiliency refers to the ability of a company’s supply chain to quickly and effectively respond to disruptions and recover from them. Disruptions in the supply chain can come from a variety of sources, such as natural disasters, geopolitical conflicts, supplier bankruptcies, and pandemics. These disruptions can have far-reaching consequences, including increased costs, lost revenue, reputational damage, and decreased customer satisfaction.
The Impact of Supply Chain Resiliency on Organizational Performance
Research has shown that companies with resilient supply chains are better able to manage disruptions and maintain business continuity, leading to improved organizational performance. For example, a study by Zhang et al. (2019) found that companies with resilient supply chains had higher levels of customer satisfaction, lower inventory costs, and higher profits than those with less resilient supply chains.
Another study by Choi and Hong (2018) found that companies with resilient supply chains were more likely to survive and recover from disruptions, and were better able to adapt to changing market conditions. Furthermore, companies with resilient supply chains were able to respond more quickly to customer demands, improving their overall competitiveness.
Strategies for Enhancing Supply Chain Resilience
So, how can companies enhance their supply chain resiliency? There are several strategies that companies can employ to improve their resiliency, including:
Developing a Risk Management Plan
Companies should develop a comprehensive risk management plan that identifies potential disruptions and outlines strategies for mitigating their impact. Developing a comprehensive risk management plan is essential for enhancing supply chain resiliency. The risk management plan should identify potential risks and disruptions that could impact the supply chain, such as natural disasters, political unrest, supplier bankruptcies, and cyber attacks. Once the risks have been identified, the plan should outline strategies for mitigating their impact and minimizing disruption to the supply chain.
The risk management plan should be developed in collaboration with all stakeholders involved in the supply chain, including suppliers, logistics providers, and customers. This collaborative approach ensures that all parties are aware of the potential risks and are prepared to respond to any disruptions that may occur.
One key aspect of the risk management plan is contingency planning. Contingency planning involves developing backup plans and alternate strategies for managing disruptions. For example, if a key supplier experiences a disruption, the risk management plan should outline strategies for identifying and qualifying alternative suppliers to ensure that the supply chain can continue to function.
Building Redundancy into the Supply Chain
Companies can build redundancy into their supply chain by identifying alternative suppliers and transportation modes, and maintaining a buffer of inventory and production capacity.
Developing strong relationships with suppliers is another critical component of enhancing supply chain resiliency. Strong relationships can help companies manage risks, identify potential disruptions, and respond to disruptions quickly and effectively. Companies that have strong supplier relationships are better equipped to manage disruptions, as they can rely on their suppliers for support during challenging times.
To build strong supplier relationships, companies should focus on open communication, collaboration, and trust. Communication is essential for building strong relationships, as it enables companies to share information and expectations with their suppliers. Companies should communicate regularly with their suppliers and involve them in decision-making processes that impact the supply chain.
Collaboration is another key factor in building strong supplier relationships. Companies should work closely with their suppliers to identify potential risks and develop strategies for managing those risks. This collaborative approach ensures that suppliers are invested in the success of the supply chain and are prepared to support the company during disruptions.
Trust is also critical for building strong supplier relationships. Companies should establish trust by being transparent and honest with their suppliers. This includes sharing information about the company’s operations, financial performance, and future plans. When suppliers trust the company, they are more likely to be responsive and supportive during challenging times.
Another strategy for building strong supplier relationships is to diversify the supply base. Companies that rely on a single supplier for critical inputs are more vulnerable to disruptions. By diversifying the supply base, companies can reduce their reliance on any one supplier and minimize the impact of disruptions.
Investing in Technology
The adoption of digital technologies, such as blockchain and artificial intelligence, can significantly improve supply chain resiliency by enhancing supply chain visibility, enabling real-time tracking and monitoring, and improving risk management.
Investing in technology and automation is another critical component of enhancing supply chain resiliency. Technology and automation can help companies better manage risks, improve efficiency, and respond to disruptions quickly and effectively. By investing in technology and automation, companies can enhance their ability to monitor and manage their supply chains, as well as improve their response times to disruptions.
One technology that can be particularly useful for enhancing supply chain resiliency is real-time data analytics. Real-time data analytics enables companies to monitor their supply chains in real-time, identify potential disruptions, and respond quickly to those disruptions. Companies can use real-time data analytics to track shipments, monitor inventory levels, and identify potential bottlenecks or delays in the supply chain.
Another technology that can be useful for enhancing supply chain resiliency is predictive analytics. Predictive analytics uses historical data to identify potential risks and disruptions before they occur. Companies can use predictive analytics to forecast demand, identify potential supply chain disruptions, and develop contingency plans to manage those disruptions.
Investing in automation can also help companies improve supply chain resiliency. Automation can help companies improve efficiency, reduce costs, and respond quickly to disruptions. For example, companies can use automation to streamline the production process, reduce lead times, and improve product quality. Additionally, automation can help companies respond quickly to disruptions by enabling them to quickly shift production to alternative facilities or suppliers.
Collaborating with Suppliers
Companies can improve their resiliency by collaborating closely with their suppliers, sharing information and resources, and working together to identify and mitigate potential disruptions.
Developing contingency plans is another critical component of enhancing supply chain resiliency. Contingency plans enable companies to prepare for and respond to disruptions quickly and effectively. By developing contingency plans, companies can minimize the impact of disruptions on their supply chains and maintain operations during challenging times.
Contingency planning involves identifying potential risks and disruptions to the supply chain, as well as developing strategies for managing those risks. Companies should consider a range of potential risks, including natural disasters, supplier bankruptcies, geopolitical risks, and economic downturns. By identifying potential risks and disruptions, companies can develop contingency plans that enable them to respond quickly and effectively to those disruptions.
Contingency plans should include both short-term and long-term strategies for managing disruptions. Short-term strategies may include identifying alternative suppliers or sourcing materials from different regions. Long-term strategies may include diversifying the supply base, investing in automation and technology, or establishing redundant facilities in different geographic locations.
Developing contingency plans also involves regular testing and updating of those plans. Companies should regularly test their contingency plans to ensure that they are effective and up-to-date. This may involve conducting simulation exercises or tabletop exercises to identify potential weaknesses in the plan. Companies should also update their contingency plans regularly to reflect changes in the supply chain or the business environment.
Establishing a Crisis Management Plan
Companies should develop a crisis management plan that outlines procedures for responding to disruptions, including communication protocols, decision-making processes, and contingency plans.
Building strong relationships with suppliers is another critical component of enhancing supply chain resiliency. Strong supplier relationships can help companies manage risks, improve efficiency, and respond quickly to disruptions. By building strong relationships with suppliers, companies can establish trust, enhance communication, and collaborate on developing solutions to potential disruptions.
Building strong supplier relationships involves more than just signing contracts and placing orders. It involves establishing open lines of communication, sharing information, and working collaboratively to address potential risks and disruptions. Companies should consider establishing regular meetings or calls with suppliers to discuss potential risks and opportunities for collaboration.
In addition, companies should consider working with suppliers to develop joint contingency plans. Joint contingency plans enable companies and suppliers to collaborate on managing disruptions, rather than simply shifting the responsibility to the supplier. By working together to develop contingency plans, companies and suppliers can identify potential risks and develop strategies for managing those risks collaboratively.
Building strong supplier relationships also involves establishing clear expectations and metrics for performance. Companies should work with suppliers to establish clear expectations for delivery times, quality standards, and pricing. Additionally, companies should establish metrics for measuring supplier performance, including on-time delivery rates, defect rates, and responsiveness to inquiries or requests.
Leveraging Technology and Innovation
Companies should continuously monitor and evaluate their supply chain performance, using metrics such as lead times, inventory levels, and supplier performance, to identify areas for improvement and ensure that their supply chain remains resilient.
Leveraging technology and innovation is another critical component of enhancing supply chain resiliency. Technology and innovation can help companies improve efficiency, reduce costs, and respond quickly to disruptions. By embracing technology and innovation, companies can gain a competitive advantage and enhance their supply chain resiliency.
There are several ways in which companies can leverage technology and innovation to enhance their supply chain resiliency. One way is by investing in supply chain visibility tools. Supply chain visibility tools enable companies to track inventory levels, monitor supplier performance, and identify potential risks or disruptions in real-time. By leveraging these tools, companies can quickly respond to disruptions and minimize the impact on their supply chains.
Another way in which companies can leverage technology and innovation is by investing in automation. Automation can help companies reduce costs, improve efficiency, and enhance quality. By automating repetitive tasks, such as order processing or inventory management, companies can free up resources to focus on more strategic tasks, such as developing contingency plans or building strong supplier relationships.
In addition, companies can leverage innovation to develop new products or services that enhance supply chain resiliency. For example, companies can develop new materials or packaging solutions that reduce the risk of damage during transportation or storage. By developing innovative solutions, companies can gain a competitive advantage and enhance their supply chain resiliency.
Conclusion
In today’s increasingly complex and interconnected global business environment, supply chain resiliency is critical to organizational performance. Companies that invest in enhancing their supply chain resiliency are better able to manage disruptions and maintain business continuity, leading to improved customer satisfaction, lower costs, and higher profits.
By adopting strategies such as developing a risk management plan, building redundancy into the supply chain, investing in technology, collaborating with suppliers, establishing a crisis management plan, and continuously monitoring and evaluating performance, companies can enhance their supply chain resiliency and improve their overall performance.
References
Choi, T. Y., & Hong, Y. (2018). The impact of supply chain resilience on operational performance: a resource-based view. International Journal of Production Research, 56(1-2), 384-397.
Did you find any useful knowledge relating to supply chain resilience on organisational performance in this post? What are the key facts that grabbed your attention? Let us know in the comments. Thank you.
Staffing Challenges in Long Term Care Nursing and Solutions
The purpose of this report is to analyze and discuss the staffing challenges that exist in long term care nursing and the implications it has on patient care. The report presents a brief on the problem first and then presents some of the possible solutions that could be undertaken by the administrators of health care institutions that are dealing with actual nursing staff shortages.
The Nursing profession is one that has been known amongst the healthcare profession, to experience several challenges. Staffing challenges have been noted to be one of the primary health care challenges with respect to the nursing profession. These challenges have been known to not only affect the nurses, but other health care professionals who work with nurses on a daily basis.
This could also affect the quality of care they tend to provide for their patients. The purpose of this report is to discuss how staffing issues in nursing (with emphasis on long term care) has implications on patient care. The main purpose of this paper is to analyze and present solutions and recommendations for the issue.
The factors such as increasing staffing by means of including a more widened demographic for nursing training and more are presented using the support of existing literature research. These recommendations can be made use of administration of health care facilities to improve with respect to their staffing shortage problems.
Shortage of Registered Nurses (RNs) and subsequent degradation in quality of patient care has been the most critical issue that the whole medical community across United States is facing in recent years. Nurses play a significant role in patient’s recuperation right from the admission to hospital to his discharge and later at home for rehabilitation till he is capable of looking after himself.
But the current staffing issues of nurses could result in a complete collapse of healthcare system. Therefore this report is set to review staffing challenges in long term nursing, its causes and consequences on the field of medicine and the suggested possible solutions in a more holistic way. A myriad of elements are considered and the solution is framed with these elements. This report also recommends few strategies and a feasible plan of action for successfully overcoming the challenge.
Issue Analysis
The sharp decline in mortality rates and increase in life expectancy has led to a greater proportion of old population in 20th century. This has led to more emphasis on aged care. The baby boomers are now in their retirement ages fast approaching the time where they might require more health care. Knickman, & Snell, 2002, assess how there will be challenges in caring for the baby boomer generation as they crossing their ages of 60.
In a series of analyses that was conducted with respect to types of challenges that would be faced, it was seen that the baby boomer generation will require much long terms care and this would lead to an economic burden for the state and also the health care system.
In addition there has also been noted that the incidences of different diseases have increased, epidemic of various diseases and increase in accidents have ultimately escalated demand for RNs. Diseases related to obesity and cardiovascular problems are on the high (Van Gaal,et al, 2006).
Diseases such as this lead to the increase in the number of people that require long term care. The proportion of aged people requiring long term care is still higher, yet the number of other demographics that require long term care has also increased contributing to the nursing shortage scenario.
Insufficient number of graduate nursing programs and faculty, inadequate classroom space, less developed clinical sites and preceptors, and budget limitations put restrictions on nursing program enrollments, all of which can contribute to staffing challenges within the health sector.
This generates very small number of qualified RNs that fit into the requirement of highly sensitive cases (Drury, Francis & Chapman, 2009). The problem of there being insufficient nursing programs directly leads to lesser students graduating from the program.
However it is also noticed that students might be reluctant to take up nursing programs like they did before. Also the ones that do take up nursing education might also end in giving it up because of the stress levels that are generated in this work. Extra working hours, low wages, inability to devote time for personal life and extended workload impose more stress on RNs.
Lack of job satisfaction and depreciation of job status further discourage them to continue in nursing profession (Peterson, 2001). Crash of revenues directly impacts into slashing the nursing staff in hospitals which makes this nursing job very unstable. This deficiency of certified RNs add patient complications, medication errors, death rates, safety problems, longer hospital stays, nurse fatigue and burnout and unpleasant experience for both patient and nurses (Wright & Bretthauer, 2010).
Staffing challenges is not a problem in current times alone. The nursing shortage has been a problem for a longer time now. As of the 1990’s it was noticed that the nursing shortage was existent in the country as with many other global nations. Nursing positions were cut in the countries like the United States because health care expenditure was increasing with respect to managed care.
Public and private insurance reimbursement was also at an all time low and this lead to financial difficulties for hospitals which reduced the number of nurse practitioner working with them. In addition to this problem it was also noticed that most of the hospital administrators did not consider the nursing profession in its actual light.
They did not understand the value of the nursing professional and did much restructuring to improve finances that were highly focused on decreasing the number of nurses employed with the organization.
This asymmetry in power was seen to have made much of the nurses to remain underpowered (McVicar, 2003). Nurses that went out of their professions moved on to become housewives and hence lost the training and expertise that made them nurses or moved onto other professions in different fields. With understaffing, the work performed by nurses was done by assistive personnel. The existing nurses could not work with the short staffing. A National Survey that was conducted on nurses in the year 2005 indicates that more than a million of the U.S. registered nurses chose to leave their jobs either because of the instability of their positions or because they could not perfume as was required because of understaffing at their place (The Truth about Nursing, 2007).
In current times, social issues also contribute to nursing shortage. The nursing profession is still viewed as a gendered profession meaning the profession is still a female dominated profession. Women are seen as natural caregivers in socio-cultural contexts and men are quite reluctant to enter nursing professions.
Research indicates that men might face a social stigma when they want to enter nursing professions. In countries such as the United States only an approximate 6 percent of the population is seen to be in the nursing profession. With the current workforce rapidly aging, soon the nursing shortage problem will exacerbate if the current shortage is not filled with a younger workforce.
The workforce will also need training from senior peers and for the nurses to be trained in a qualitative manner, it is necessary that the shortage problem be addressed and training commence as soon as possible under existing senior nurses.
Solutions to Staffing Challenges
Some of the problems such as the aging of baby boomers that puts them in the situation where they need more aged care cannot be resolved. So these issues contributing to the nursing shortage cannot be handled, yet there is significant other issues as pointed out that could be handled well.
Primarily it has been noted that the number of nursing school graduates have become lesser. Adequate funds should be arranged to encourage graduate schools to improvise nursing programs by facilitating necessary infrastructure and services, and appointing experienced teaching faculty.
A special attention should be provided to verify the competency of undergraduate as well as the graduate curriculum to produce skilled and knowledgeable RNs in future (Peterson, 2001). This solution is the best long term solution, as it will ensure that there are more nurse practitioners in future. However it is necessary that this solution be implemented by considering the implications of implementation.
For instance, in the issues section, it was pointed out that as early as in the 1990’s the problems of nursing shortage was seen to be created by administrators who did not understand the value of the profession. They created budget cuts and staff cuts that led to job loss for nurses.
Staffing Challenges in Long Term Care Nursing and Solutions
The mindset of health care administrators needs to be changed. The power asymmetrical has to be set right. Only then future nursing practitioners will have sustained profession. Where a student question how sustainable their future is as a nursing practitioner then they might be reluctant to enter the profession itself.
RNs can postpone their retirement age which would allow them to work longer and let the new staff learn from their valuable experiences. To eliminate imbalance after their retirement, mix of young as well as matured RNs should be recruited to impart diversity (Drury, Francis & Chapman, 2009). In this way the raining for the younger nursing practitioners could be more qualitative.
An optimal staffing framework should be constructed to ensure safe and quality patient-care, and fulfillment of organization’s financial constraints. It would guarantee better salary, stability, job satisfaction and pressure-free working conditions for staff. Coordinated scheduling and planning can reduce overtime, undesirable working hours and also the labor costs with great margins (Wright & Bretthauer, 2010).
Community should be encouraged to play their part in long term care. Community, meaning the family, friends, local volunteers and more should be able to assist in long term care and this would help in managing the nursing shortage problem till a long term solution is implemented.
Recommended Action
To implement the possible solutions effectively, the administration as well as the NGOs should contribute monetarily to ease the primary need of financial expenditure. Every state administration should accumulate data of their respective patient population that need unique nursing care such as old age group, incurable disease, contagious patients etc.
By comparing it with the availability of nursing staff and resources, an optimal and flexible staffing approach should be developed for at least next 5 years and accordingly the funds should be allocated wherever required (Wright & Bretthauer, 2010). Depending upon the need, the RN staff should be imported or exported between the states by mutual agreement (Peterson, 2001). It would provide correct number of nursing staff with mixture of correct qualification, sufficient experience and appropriate skill.
Working on the nursing staff shortage problem as of present, surveys have been conducted to understand why the shortage is an actual ongoing problem for nursing practitioners (from the Progress Report). The survey itself was quite problematic as most of the hospital personnel were reluctant to give answers to the surveys.
A major attitudinal change is hence required here. Secondly (as indicated in the Progress report) there are more future accomplishments to be completed. Some of the issues that one would expect to encounter is when coming up with the incentives to encourage low grade nurses and nursing assistants to get back to school or training to become more quality workers. This form of incentive negotiation has to be done with the administrators.
The nursing practitioners also have to be inspired with long term vision so they go back to retrain and they also have to be inspired by the institution so that they would be loyal enough to return.
Secondly, it is necessary to include benefits program for the nurse practitioners. Long term career training plans must be made, and by working with the human resources motivational reimbursement packages and more have to be created. Where possible it is also necessary to offer them other forms of job security.
Conclusion
Nursing is the backbone of healthcare industry. Though it is affected by staffing difficulties, government of all the states in America should work in collaboration to assess the current situation and outcomes of implemented actions. It would enable them to decide upon the best solution apt for the longevity of the business.
References
Drury, V., Francis, K. & Chapman, Y. (2009). Where Have All the Young Ones Gone: Implications for the Nursing Workforce. Web. The Online Journal of Issues in Nursing, 14 (1).
Fox, R. L., & Abrahamson, K. (2009, October). A critical examination of the US nursing shortage: Contributing factors, public policy implications. In Nursing Forum (Vol. 44, No. 4, pp. 235-244). Blackwell Publishing Inc.
Knickman, J. R., & Snell, E. K. (2002). The 2030 problem: caring for aging baby boomers. Health services research, 37(4), 849-884.
McVicar, A. (2003). Workplace stress in nursing: a literature review. Journal of advanced nursing, 44(6), 633-642.
Peterson, C. (2001). Nursing Shortage: Not a Simple Problem – No Easy Answers. Web. The Online Journal of Issues in Nursing, 6 (1).
The Truth About Nursing. (2007). Nursing Shortage.
Van Gaal, L. F., Mertens, I. L., & Christophe, E. (2006). Mechanisms linking obesity with cardiovascular disease. Nature, 444(7121), 875-880.
Wright, D. & Bretthauer, K. (2010). Strategies for Addressing the Nursing Shortage: Coordinated Decision Making and Workforce Flexibility. Decision Sciences, 41 (2): 375- 400.
The Executive Assessment – The Deans and directors of the top ten EMBA global B-Schools attended a workshop in 2015 organized by GMAC, the organization that owns the GMAT program. Most agreed that some remarkable EMBA candidates were hesitant, unable or completely reluctant to take the GMAT. Ultimately two questions remained: Were there remarkable candidates who considered the GMAT as too high an obstacle? Could an alternate evaluation help bring such applicants into the EMBA programs?
Evaluation tests like the GMAT are necessary to test the quantitative aptitude of the applicant to see whether they will be able to handle the rigours of the EMBA program.
The tests are important to test the understanding of the applicants with regards to mathematical concepts such as statistics and algebra, and for students for whom English is a secondary language to demonstrate that they possess the aptitude to peruse and comprehend complex writings.
After the workshop, GMAC took all inputs and observed the concerns and needs and customized a test that would be able to measure the abilities of the candidates to manage the rigour of an EMBA classroom.
Today, the Executive Assessment is acknowledged by more than ninety EMBA programs at top notch business schools. The latest school to recognize the exam for admission to its EMBA program is Vanderbilt’s Owen School of Management.
The Executive Assessment
Since the test is relatively new, there isn’t much study material available for preparation apart from that available on the official website of the GMAT. The Executive Assessment assesses candidates on higher-order reasoning in three 30 minute long sections: Integrated Reasoning, Verbal Reasoning and Quantitative Reasoning.
Each section gives a rough score from 0 to 20. Those scores are combined to give a total score within 100 to 200. This score is also considered valid for five years like the GMAT/GRE but you can take the EA only twice.
Retaking the Executive Assessment
Executive Assessment participants can take the test twice and usually scores improve with the subsequent attempt. For test takers hoping to better their score, consider these preparation tips:
Analyze
Evaluate your initial test score for each section. This will help you to figure out your weak spots and enable you to achieve balance across all three sections.
Practice
it is a fact that only practice shall make you perfect. Sample practice papers are available on the GMAC website.
Relax
You are already aware of the format by now, so try and stay calm; not only will it help you keep focus, it will also help you do justice to your preparation.
Advice and tips
You can take the EA twice. Therefore, make the first attempt count.
A calculator is allowed only for the Integrated Reasoning section and not for the Quantitative Reasoning section. Plan accordingly!
Find mistake patterns when you work through practice problems. Brush up on your fundamentals to avoid repetitive mistakes.
Practice using a timer. This helps to uncover mistakes that you tend to make when working against the clock. Most times you will realise that there will be small, silly mistakes that can be corrected easily.
The standard study and practice time is between 10 and 20 hours. However, if you can squeeze in some extra time for the Quantitative Reasoning and Integrated Reasoning sections, it will pay off in the longer run.
The Executive Assessment EMBA
We offer a broad range of MBA dissertation topics for students to choose from, covering a wide variety of subject matters. Our dissertation topics include topics related to the sciences, humanities, social sciences, and much more.
We have experienced writers who are knowledgeable in all areas and can provide expert guidance and support when it comes to choosing dissertation topics as well as helping you with the entire writing process.
If you’re looking for resources to help you write your dissertation, there are many available. From research databases and libraries to writing coaches and online courses, there is a range of options available to support your writing journey. Additionally, your university may offer extra support such as proofreading services.
If you enjoyed reading this post on the Executive Assessment, I would be very grateful if you could help spread this knowledge by emailing this post to a friend, or sharing it on Twitter or Facebook. Thank you.